
In this article, we explore what one may learn from the information extracted from Bitcoin Blockchain using Google Cloud Platform BigQuery and Datalab. The first topic is about the anonymity of Bitcoin and the second is comparing the return on Bitcoin to Gold.
The blockchain data used is extracted and processed with heuristic algorithms to identify clustering of transactions that belong to same entities through graph analysis: see detail https://github.com/schloerke/Bitcoin-Transaction-Network-Extraction for more detail.
A blockchain is a distributed ledger, the data of the entire network will be downloaded by running on a full node. The current data size is about 160G. It will take a few days of running a full mining node before getting blockchain data up to date. The information on Bitcoin pricing (or exchange rate) is still sparse and many are in different currencies, therefore the sourcing and normalizing data is a challenge.An example source is http://api.bitcoincharts.com/v1/csv/.
Google Cloud Storage and BigQuery is the main ETL tool and storage: it enables you to start exploratory analysis right away, without the need to setup and maintain an elastic high performance computing cluster and storage. It likes having a robotic assistant on rent who could prepare food ingredients fast when one is experimenting with them to develop new receipts.
ETL
Raw data is often received in various of formats and can lead to extended run times for ETL with large datasets. For certain transformations, Biq Query provides a simple and fast path for completing the tasks. For example, the query shown below transforms the "daytime format from integer -- 20090109035439 -- to TIMESTAMP format.
SELECT txId, sender, receiver, value, outAddrId, outIndex, blockHt,
TIMESTAMP(
CONCAT(
CAST (INTEGER(time/10000000000) AS STRING),'-',
CAST (INTEGER((time%10000000000)/100000000)AS STRING),'-',
CAST (INTEGER((time%100000000)/1000000) AS STRING),' ',
CAST (INTEGER((time%1000000)/10000) AS STRING),':',
CAST (INTEGER((time%10000)/100) AS STRING),':',
CAST (INTEGER(time%100) AS STRING)
)) AS txnTS
FROM blockchain.user_edges_raw
In this example, the transformation of 5.83G of data is processed in 136 seconds.
Exploring Data using Datalab
(Texts in red are codes, and texts in blue are output in Datalab(Jupyter) notebook.)
- Number of transactions over time:
Finding trend, presumably, is the first place to start when exploring new datasets. The example here is to look at the number of transactions done over time. It is not certain whether the timestamp information is adjusted for time zones.
import datalab.bigquery as bq
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.dates import num2date
from matplotlib.dates import date2num
from matplotlib.finance import candlestick_ohlc
import json
from pprint import pprint
from PyQt4 import QtGui, QtCore
import urllib
import requests
import sys
import gzip
import urllib
import datetime
import numpy as np
import pandas as pd
import time
import re
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.dates import num2date
from matplotlib.dates import date2num
from matplotlib.finance import candlestick_ohlc
import json
from pprint import pprint
from PyQt4 import QtGui, QtCore
import urllib
import requests
import sys
import gzip
import urllib
import datetime
import numpy as np
import pandas as pd
import time
import re
%%sql --module txn
select count(txid) as no_of_txn, txnTS from blockchain.userEdges
group by txnTS
select count(txid) as no_of_txn, txnTS from blockchain.userEdges
group by txnTS
df = bq.Query(txn).to_dataframe()
df.plot(x='txnTS',y='no_of_txn')
<matplotlib.axes._subplots.AxesSubplot at 0x7f8a9305fa10>

- The next is to explore which addresses to which bitcoins have sent. There are few well known addresses http://www.theopenledger.com/9-most-famous-bitcoin-addresses/. It could be interesting to trace the transactions and and geo-locations of where they are initiated.
%%sql --module btc_sinks
SELECT a.outAddrId, b.address, sum(a.value) as btc_amount
FROM (
SELECT
outAddrId, value
FROM [plasma-centaur-859:blockchain.userEdges]
) a
JOIN EACH (
SELECT
id, address
FROM
[plasma-centaur-859:blockchain.address]
) b
ON a.outAddrId = b.id
WHERE a.outAddrId = b.id
GROUP BY 1,2
ORDER BY 3 DESC
LIMIT 500
SELECT a.outAddrId, b.address, sum(a.value) as btc_amount
FROM (
SELECT
outAddrId, value
FROM [plasma-centaur-859:blockchain.userEdges]
) a
JOIN EACH (
SELECT
id, address
FROM
[plasma-centaur-859:blockchain.address]
) b
ON a.outAddrId = b.id
WHERE a.outAddrId = b.id
GROUP BY 1,2
ORDER BY 3 DESC
LIMIT 500
topSinks=bq.Query(btc_sinks).to_dataframe()
topSinks
outAddrId
|
address
|
btc_amount
| |
0
|
2536935
|
13hKjDXD5WFZreZzfAGFpgajEdMotuxRvk
|
2.546664e+07
|
1
|
2298461
|
17URSNmoNqAunWUa3fi6rx22s8BJkAEkPT
|
5.706508e+06
|
2
|
7996957
|
19Hx7xow6RKTcqney12KYFsZzKpRib8iG1
|
5.005462e+06
|
3
|
17322005
|
17zRM14vC2z4QtSnANdnthY9LYovnfV84Z
|
3.403557e+06
|
4
|
12557222
|
18T1hzjughXdG4ucUh8ACDmCYK3baJpCEf
|
1.771494e+06
|
5
|
11204757
|
17wWMcge7fWV9r6JCLRc4iVmPnW6yGhNUc
|
1.573960e+06
|
6
|
19314133
|
1NQvPqe2op85q9X9hgSY5GxJERmqoSBmCf
|
1.569076e+06
|
7
|
3524361
|
1LWBSqy4s7yZrKU6GfFzx7YmsHcXfuksUZ
|
1.016878e+06
|
8
|
6835733
|
16YgsR6EGWtx3N2X3c6DvTesrKab9qriu6
|
9.550461e+05
|
9
|
7033638
|
14486XytdA6yKh4cGUGzrmxccaSznXeAAD
|
9.228888e+05
|
10
|
3451099
|
13SH2dehm6oxFav9dMc7i1NpMsgTVDWbpj
|
9.014718e+05
|
11
|
3517603
|
1idWZBys5AVK8PBZL2JHwFVe7vnFCe4Qk
|
8.582446e+05
|
12
|
13013852
|
17R1QnCThtmjkFTm7Xbrq14TyhA2thHLSP
|
8.181718e+05
|
13
|
21419578
|
1CBhbofpCiHeYekqqvtsD4gN7VRXyy1kV5
|
7.964936e+05
|
14
|
2817770
|
18om4X8rebEEGYtigU458Z9v8cFajdXshh
|
6.133265e+05
|
15
|
3524210
|
1PFbC2mZTRfeqRFkLRVeWjjHiugmte5Qhi
|
6.120741e+05
|
...
|
...
|
...
|
...
|
496
|
403757
|
17wwDDkFSsyygHJSAwAVbG1RRVrF3xS293
|
7.900000e+04
|
497
|
32647318
|
12H9E9DpRnYDxRRMRmd8nW9mnZNjd8s2yK
|
7.869300e+04
|
498
|
3025901
|
19FHRfZAiroNZEqBJjsFemr3NvKdEzJrQ4
|
7.863082e+04
|
499
|
65395
|
19DRFyzVhG7CwfAQgn2AcpBtx1vTaTuSiL
|
7.829894e+04
|
500 rows × 3 columns
- Each address can be examined for unspent coins.
import json
from blockcypher import get_address_overview
import time
from blockcypher import get_address_overview
import time
def getAddressInfo(smallDf, token):
for index, row in smallDf.iterrows():
data = (get_address_overview(row['address'],'btc',token))
final_n_tx = data['final_n_tx']
n_tx = data['n_tx']
unconfirmed_balance = data['unconfirmed_balance']
final_balance = data['final_balance']
balance = data['balance']
total_sent = data['total_sent']
address = data['address']
total_received = data['total_received']
print(address, total_received, balance, final_n_tx, total_sent)
temp = {
"address": address,
"final_n_tx": final_n_tx,
"n_tx": n_tx,
"unconfirmed_balance": unconfirmed_balance,
"final_balance": final_balance,
"balance": balance,
"total_sent": total_sent,
"total_received": total_received,
}
addresses.append(temp)
#introduce pause
time.sleep (100.0 / 1000.0);
Most API services have rate limit, so short pause and sharding data are required to collect fuller set of data. The API token ‘62aa1f7dbc694b3e939fa8a2b9762f9f’ used below is obtained from Blockcypher (https://www.blockcypher.com).
for index, row in smallDf.iterrows():
data = (get_address_overview(row['address'],'btc',token))
final_n_tx = data['final_n_tx']
n_tx = data['n_tx']
unconfirmed_balance = data['unconfirmed_balance']
final_balance = data['final_balance']
balance = data['balance']
total_sent = data['total_sent']
address = data['address']
total_received = data['total_received']
print(address, total_received, balance, final_n_tx, total_sent)
temp = {
"address": address,
"final_n_tx": final_n_tx,
"n_tx": n_tx,
"unconfirmed_balance": unconfirmed_balance,
"final_balance": final_balance,
"balance": balance,
"total_sent": total_sent,
"total_received": total_received,
}
addresses.append(temp)
#introduce pause
time.sleep (100.0 / 1000.0);
Most API services have rate limit, so short pause and sharding data are required to collect fuller set of data. The API token ‘62aa1f7dbc694b3e939fa8a2b9762f9f’ used below is obtained from Blockcypher (https://www.blockcypher.com).
addresses=[]
df_new1, df_new2, df_new3 = topSinks[:199], topSinks[200:399], topSinks[400:499]
getAddressInfo(df_new1,'62aa1f7dbc694b3e939fa8a2b9762f9f')
df_new1, df_new2, df_new3 = topSinks[:199], topSinks[200:399], topSinks[400:499]
getAddressInfo(df_new1,'62aa1f7dbc694b3e939fa8a2b9762f9f')
(u'13hKjDXD5WFZreZzfAGFpgajEdMotuxRvk', 23231010, 0, 2, 23231010)
(u'17URSNmoNqAunWUa3fi6rx22s8BJkAEkPT', 1147262900, 0, 2, 1147262900)
(u'19Hx7xow6RKTcqney12KYFsZzKpRib8iG1', 35552011, 0, 2, 35552011)
(u'17zRM14vC2z4QtSnANdnthY9LYovnfV84Z', 199999950000, 0, 2, 199999950000)
(u'18T1hzjughXdG4ucUh8ACDmCYK3baJpCEf', 98000004, 0, 2, 98000004)
(u'17wWMcge7fWV9r6JCLRc4iVmPnW6yGhNUc', 1064361310, 0, 2, 1064361310)
(u'1NQvPqe2op85q9X9hgSY5GxJERmqoSBmCf', 81000000, 0, 3, 81000000)
(u'1LWBSqy4s7yZrKU6GfFzx7YmsHcXfuksUZ', 214460712207, 0, 2, 214460712207)
(u'16YgsR6EGWtx3N2X3c6DvTesrKab9qriu6', 1390000, 0, 2, 1390000)
(u'14486XytdA6yKh4cGUGzrmxccaSznXeAAD', 3922905117, 0, 2, 3922905117)
(u'13SH2dehm6oxFav9dMc7i1NpMsgTVDWbpj', 1800000, 0, 2, 1800000)
(u'1idWZBys5AVK8PBZL2JHwFVe7vnFCe4Qk', 1195000, 0, 2, 1195000)
(u'17R1QnCThtmjkFTm7Xbrq14TyhA2thHLSP', 283524240, 0, 2, 283524240)
(u'1CBhbofpCiHeYekqqvtsD4gN7VRXyy1kV5', 50000000, 0, 2, 50000000)
(u'18om4X8rebEEGYtigU458Z9v8cFajdXshh', 78605090, 0, 2, 78605090)
(u'1PFbC2mZTRfeqRFkLRVeWjjHiugmte5Qhi', 12760258243, 0, 162, 12760258243)
(u'17URSNmoNqAunWUa3fi6rx22s8BJkAEkPT', 1147262900, 0, 2, 1147262900)
(u'19Hx7xow6RKTcqney12KYFsZzKpRib8iG1', 35552011, 0, 2, 35552011)
(u'17zRM14vC2z4QtSnANdnthY9LYovnfV84Z', 199999950000, 0, 2, 199999950000)
(u'18T1hzjughXdG4ucUh8ACDmCYK3baJpCEf', 98000004, 0, 2, 98000004)
(u'17wWMcge7fWV9r6JCLRc4iVmPnW6yGhNUc', 1064361310, 0, 2, 1064361310)
(u'1NQvPqe2op85q9X9hgSY5GxJERmqoSBmCf', 81000000, 0, 3, 81000000)
(u'1LWBSqy4s7yZrKU6GfFzx7YmsHcXfuksUZ', 214460712207, 0, 2, 214460712207)
(u'16YgsR6EGWtx3N2X3c6DvTesrKab9qriu6', 1390000, 0, 2, 1390000)
(u'14486XytdA6yKh4cGUGzrmxccaSznXeAAD', 3922905117, 0, 2, 3922905117)
(u'13SH2dehm6oxFav9dMc7i1NpMsgTVDWbpj', 1800000, 0, 2, 1800000)
(u'1idWZBys5AVK8PBZL2JHwFVe7vnFCe4Qk', 1195000, 0, 2, 1195000)
(u'17R1QnCThtmjkFTm7Xbrq14TyhA2thHLSP', 283524240, 0, 2, 283524240)
(u'1CBhbofpCiHeYekqqvtsD4gN7VRXyy1kV5', 50000000, 0, 2, 50000000)
(u'18om4X8rebEEGYtigU458Z9v8cFajdXshh', 78605090, 0, 2, 78605090)
(u'1PFbC2mZTRfeqRFkLRVeWjjHiugmte5Qhi', 12760258243, 0, 162, 12760258243)
…
(u'1FutgpSdhCwYio5ZrSZGh68mQY9BNYhT9P', 13152165610, 0, 2, 13152165610)
(u'1CRVQTBb4gVnJjhHjKDqzNZas3exqBVNeQ', 87800000, 0, 2, 87800000)
(u'1HjDauL2kth6KJUz5vX198Nvp1xN1hgYRb', 39184702881299, 40000, 396890, 39184702841299)
(u'13HFqPr9Ceh2aBvcjxNdUycHuFG7PReGH4', 38788846237971, 43000, 396569, 38788846194971)
(u'1NWVkQJGNagiKXDPWs364LL71aNRuv1usU', 2055378000, 0, 2, 2055378000)
(u'1NDpZ2wyFekVezssSXv2tmQgmxcoHMUJ7u', 39113236432903, 83001, 397702, 39113236349902)
(u'1Ns6m3RagT5pRNYwxfrYvXS9neUWMYLL7u', 11993137, 1, 3, 11993136)
(u'15fXdTyFL1p53qQ8NkrjBqPUbPWvWmZ3G9', 39357308117256, 28000, 397414, 39357308089256)
(u'17i5LFxeStN9eVzZCTjpmrzk1NNb9c23fG', 2057872000, 0, 2, 2057872000)
(u'1JYwZ8RBRbbgyT5P6QSFVmAdciqcUB7q6Z', 1425000000000, 0, 2, 1425000000000)
(u'1xP3ouLDbuHqgMfg1xyRFfT4o9UJm6RdP', 396670000, 0, 2, 396670000)
(u'15qXBcz51afUKCyZJ8EmdGrrswQnHXUCEV', 36775761, 0, 2, 36775761)
(u'16JBaxknhiMXSWEbrs3LZ8nwLGJabqnoRH', 1568541321900, 0, 2, 1568541321900)
(u'1H591vi5RtA9UXapERSSEmFz8enFN8EqBb', 3955213, 3955213, 22, 0)
(u'1Dfq5VJBzW5dwFJDq4Tv9iinA7pcvPwWps', 1302347, 0, 2, 1302347)
(u'1ByBuY8hcYS5u2GbMhWNWQjf5QvPCFy9NJ', 5013984881, 0, 2, 5013984881)
(u'1BjM7XxmPvgEvoTrJbSJJ7BxUAkQTXSf8f', 353000000, 0, 6, 353000000)
(u'19L2wFKxxWBVHWLt8phYvtQB7tXZ2xvn8s', 3965500000000, 0, 2, 3965500000000)
(u'1HdAYY1eV6KtTDmBFefHGtHa4hEuU26G6k', 5000000000000, 0, 2, 5000000000000)
(u'1Pz8cYwWdgebjW46rBXpVBzy3E3B4uBrRj', 4160100000, 0, 2, 4160100000)
(u'13xstehihBmJHtX6vFNhD4n4ujW5vx5beo', 11415121, 0, 2, 11415121)
(u'1BnspJcLbQ1a2YAWWw1mFkTrudwK7ewLVh', 27315440000, 0, 2, 27315440000)
(u'16PJUzjvEApvzR1g6bM9Vod4yYgfGwjZTY', 14193600464, 0, 142, 14193600464)
(u'12HG1Hkac7kcsSy8vNKVecB8kePVxdpqBK', 10150000, 0, 2, 10150000)
(u'158LPLdQbAnqAsKrD8rUPZuGGFaMgw6jyd', 189900000, 0, 2, 189900000)
(u'158jzBkJFZJz8soep4RR1WALnVgvMD1STr', 5000000000000, 0, 2, 5000000000000)
(u'14yX4kRDME61BbM7DMnuv1PKUtk8K65J4y', 5000000000000, 0, 2, 5000000000000)
(u'1KF8gfEBEQ94tYXQNhn7Am44MGukXGLrxP', 126049100, 0, 2, 126049100)
(u'1CSZZFD7yLr24f3MUYaZWACVHBZN3vfa3M', 9991387866, 0, 22, 9991387866)
(u'14mhTBrgcTKdABnNv1oTuzuUmWKHjadq4M', 1000000, 0, 2, 1000000)
(u'12UKpwJppJ5hxYAfs1DTg1astenuFcHojz', 4000000, 4000000, 1, 0)
(u'17HDmzdYRj2bjL9wu55CRhHUiYwvKVf2p6', 190000, 0, 2, 190000)
(u'1Ev22onN7MqL3L2CLLTaY6YjYYSjXGpoCJ', 25580508185, 0, 2, 25580508185)
(u'1CRVQTBb4gVnJjhHjKDqzNZas3exqBVNeQ', 87800000, 0, 2, 87800000)
(u'1HjDauL2kth6KJUz5vX198Nvp1xN1hgYRb', 39184702881299, 40000, 396890, 39184702841299)
(u'13HFqPr9Ceh2aBvcjxNdUycHuFG7PReGH4', 38788846237971, 43000, 396569, 38788846194971)
(u'1NWVkQJGNagiKXDPWs364LL71aNRuv1usU', 2055378000, 0, 2, 2055378000)
(u'1NDpZ2wyFekVezssSXv2tmQgmxcoHMUJ7u', 39113236432903, 83001, 397702, 39113236349902)
(u'1Ns6m3RagT5pRNYwxfrYvXS9neUWMYLL7u', 11993137, 1, 3, 11993136)
(u'15fXdTyFL1p53qQ8NkrjBqPUbPWvWmZ3G9', 39357308117256, 28000, 397414, 39357308089256)
(u'17i5LFxeStN9eVzZCTjpmrzk1NNb9c23fG', 2057872000, 0, 2, 2057872000)
(u'1JYwZ8RBRbbgyT5P6QSFVmAdciqcUB7q6Z', 1425000000000, 0, 2, 1425000000000)
(u'1xP3ouLDbuHqgMfg1xyRFfT4o9UJm6RdP', 396670000, 0, 2, 396670000)
(u'15qXBcz51afUKCyZJ8EmdGrrswQnHXUCEV', 36775761, 0, 2, 36775761)
(u'16JBaxknhiMXSWEbrs3LZ8nwLGJabqnoRH', 1568541321900, 0, 2, 1568541321900)
(u'1H591vi5RtA9UXapERSSEmFz8enFN8EqBb', 3955213, 3955213, 22, 0)
(u'1Dfq5VJBzW5dwFJDq4Tv9iinA7pcvPwWps', 1302347, 0, 2, 1302347)
(u'1ByBuY8hcYS5u2GbMhWNWQjf5QvPCFy9NJ', 5013984881, 0, 2, 5013984881)
(u'1BjM7XxmPvgEvoTrJbSJJ7BxUAkQTXSf8f', 353000000, 0, 6, 353000000)
(u'19L2wFKxxWBVHWLt8phYvtQB7tXZ2xvn8s', 3965500000000, 0, 2, 3965500000000)
(u'1HdAYY1eV6KtTDmBFefHGtHa4hEuU26G6k', 5000000000000, 0, 2, 5000000000000)
(u'1Pz8cYwWdgebjW46rBXpVBzy3E3B4uBrRj', 4160100000, 0, 2, 4160100000)
(u'13xstehihBmJHtX6vFNhD4n4ujW5vx5beo', 11415121, 0, 2, 11415121)
(u'1BnspJcLbQ1a2YAWWw1mFkTrudwK7ewLVh', 27315440000, 0, 2, 27315440000)
(u'16PJUzjvEApvzR1g6bM9Vod4yYgfGwjZTY', 14193600464, 0, 142, 14193600464)
(u'12HG1Hkac7kcsSy8vNKVecB8kePVxdpqBK', 10150000, 0, 2, 10150000)
(u'158LPLdQbAnqAsKrD8rUPZuGGFaMgw6jyd', 189900000, 0, 2, 189900000)
(u'158jzBkJFZJz8soep4RR1WALnVgvMD1STr', 5000000000000, 0, 2, 5000000000000)
(u'14yX4kRDME61BbM7DMnuv1PKUtk8K65J4y', 5000000000000, 0, 2, 5000000000000)
(u'1KF8gfEBEQ94tYXQNhn7Am44MGukXGLrxP', 126049100, 0, 2, 126049100)
(u'1CSZZFD7yLr24f3MUYaZWACVHBZN3vfa3M', 9991387866, 0, 22, 9991387866)
(u'14mhTBrgcTKdABnNv1oTuzuUmWKHjadq4M', 1000000, 0, 2, 1000000)
(u'12UKpwJppJ5hxYAfs1DTg1astenuFcHojz', 4000000, 4000000, 1, 0)
(u'17HDmzdYRj2bjL9wu55CRhHUiYwvKVf2p6', 190000, 0, 2, 190000)
(u'1Ev22onN7MqL3L2CLLTaY6YjYYSjXGpoCJ', 25580508185, 0, 2, 25580508185)
- Check if top receiving addresses match known entities within certain categories. As it is mentioned earlier, the identities and entities of addresses could be found on the Internet. The function as follows is an example of retrieving category information of certain addresses.
from bs4 import BeautifulSoup
known_addresses = []
def lets_get_scraping(url, id):
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
for tr in soup.tbody.find_all('tr'):
for strong_tag in tr.find_all('strong'):
if id == 1:
temp = {strong_tag.get_text(): 1}
known_addresses.append(temp)
elif id == 2:
temp = {strong_tag.get_text(): 2}
known_addresses.append(temp)
elif id == 3:
temp = {strong_tag.get_text(): 3}
known_addresses.append(temp)
elif id == 4:
temp = {strong_tag.get_text(): 4}
known_addresses.append(temp)
return known_addresses
for i in range(17):
gambling = 'http://bitcoinwhoswho.com/search/index/index/keyword/gambling/page/{0}'.format(i)
lets_get_scraping(gambling, id=1)
print('Completed: Gambling')
for i in range(2):
charity = 'http://bitcoinwhoswho.com/search/index/index/keyword/charity/page/{0}'.format(i)
lets_get_scraping(charity, id=2)
for i in range(34):
charity = 'http://bitcoinwhoswho.com/search/index/index/keyword/donate/page/{0}'.format(i)
lets_get_scraping(charity, id=2)
print('Completed: Charity')
for i in range(17):
finance = 'http://bitcoinwhoswho.com/search/index/index/keyword/finance/page/{0}'.format(i)
lets_get_scraping(finance, id=3)
print('Completed: Finance')
for i in range(162):
exchange = 'http://bitcoinwhoswho.com/search/index/index/keyword/exchange/page/{0}'.format(i)
lets_get_scraping(exchange, id=3)
known_addresses = []
def lets_get_scraping(url, id):
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
for tr in soup.tbody.find_all('tr'):
for strong_tag in tr.find_all('strong'):
if id == 1:
temp = {strong_tag.get_text(): 1}
known_addresses.append(temp)
elif id == 2:
temp = {strong_tag.get_text(): 2}
known_addresses.append(temp)
elif id == 3:
temp = {strong_tag.get_text(): 3}
known_addresses.append(temp)
elif id == 4:
temp = {strong_tag.get_text(): 4}
known_addresses.append(temp)
return known_addresses
for i in range(17):
gambling = 'http://bitcoinwhoswho.com/search/index/index/keyword/gambling/page/{0}'.format(i)
lets_get_scraping(gambling, id=1)
print('Completed: Gambling')
for i in range(2):
charity = 'http://bitcoinwhoswho.com/search/index/index/keyword/charity/page/{0}'.format(i)
lets_get_scraping(charity, id=2)
for i in range(34):
charity = 'http://bitcoinwhoswho.com/search/index/index/keyword/donate/page/{0}'.format(i)
lets_get_scraping(charity, id=2)
print('Completed: Charity')
for i in range(17):
finance = 'http://bitcoinwhoswho.com/search/index/index/keyword/finance/page/{0}'.format(i)
lets_get_scraping(finance, id=3)
print('Completed: Finance')
for i in range(162):
exchange = 'http://bitcoinwhoswho.com/search/index/index/keyword/exchange/page/{0}'.format(i)
lets_get_scraping(exchange, id=3)
Completed: Gambling
Completed: Charity
Completed: Finance
Completed: Charity
Completed: Finance
%%sql --module address_with_most_senders
SELECT b.address as addr, count (DISTINCT sender) as sender_counts
FROM
(SELECT
sender, outAddrId
FROM [plasma-centaur-859:blockchain.userEdges]
) a
JOIN EACH (
SELECT
id, address
FROM
[plasma-centaur-859:blockchain.address]
) b
ON a.outAddrId = b.id
WHERE a.outAddrId = b.id
GROUP BY 1
ORDER BY 2 DESC
LIMIT 20000
SELECT b.address as addr, count (DISTINCT sender) as sender_counts
FROM
(SELECT
sender, outAddrId
FROM [plasma-centaur-859:blockchain.userEdges]
) a
JOIN EACH (
SELECT
id, address
FROM
[plasma-centaur-859:blockchain.address]
) b
ON a.outAddrId = b.id
WHERE a.outAddrId = b.id
GROUP BY 1
ORDER BY 2 DESC
LIMIT 20000
most_senderDf=bq.Query(address_with_most_senders).to_dataframe()
Gambling = []
Charity = []
Finance = []
for index, row in most_senderDf.iterrows():
for known in known_addresses:
k = known.keys()[0]
if k == row['addr']:
if known[k] == 1:
Gambling.append(row['addr'])
if known[k] == 2:
Charity.append(row['addr'])
if known[k] == 3:
Finance.append(row['addr'])
Charity = []
Finance = []
for index, row in most_senderDf.iterrows():
for known in known_addresses:
k = known.keys()[0]
if k == row['addr']:
if known[k] == 1:
Gambling.append(row['addr'])
if known[k] == 2:
Charity.append(row['addr'])
if known[k] == 3:
Finance.append(row['addr'])
print 'number of Gambling -> ' + str(len(Gambling))
print 'number of Charity -> ' + str(len(Charity))
print 'number of Finance -> ' + str(len(Finance))
print 'number of Charity -> ' + str(len(Charity))
print 'number of Finance -> ' + str(len(Finance))
number of Gambling -> 4
number of Charity -> 0
number of Finance -> 0
number of Charity -> 0
number of Finance -> 0
4 addresses match gambling sites. And their address:
- 17mfXdqBGHEg9xacLDNnZSHNvkDS5BBDmn
- 17mfXdqBGHEg9xacLDNnZSHNvkDS5BBDmn
- 1Eb7PfCxrn5YZr2XVoYanMmkjrHBTXDcBT
- 1Eb7PfCxrn5YZr2XVoYanMmkjrHBTXDcBT
- Rudimentary comparison of Gold and Bitcoin investment performance. Bitcoin and other crypto currencies such as Ether from Ethereum are now considered as an asset class. There is not much good historical data available, so this is mostly exploratory.
#Time series analysis USD/BTC and USD/Gold
def remove_bitcoin_date_duplicates(frame):
"""
Remove bitcoin date duplicates by using (weighted) aggregation.
"""
# Aggregate duplicate dates
frame['price'] = frame['price'] * frame['amount']
frame = frame.groupby(level=0).sum()
frame['price'] = np.round(frame['price'] / frame['amount'], 5)
"""
Remove bitcoin date duplicates by using (weighted) aggregation.
"""
# Aggregate duplicate dates
frame['price'] = frame['price'] * frame['amount']
frame = frame.groupby(level=0).sum()
frame['price'] = np.round(frame['price'] / frame['amount'], 5)
return frame
def convert_to_ohlc(frame, freq='1D'):
"""
Compute bitcoin OHLC data frame with the given frequency.
@param frame: raw bitcoin price history.
@param freq: target OHLC frequency.
"""
ohlc = frame['price'].resample(freq).ohlc()
close = frame['price'].resample(freq).last().ffill()
for column in ['open', 'high', 'low', 'close']:
ohlc[column] = np.where(np.isnan(ohlc[column]), close, ohlc[column])
ohlc['amount'] = frame['amount'].resample(freq).last()
ohlc['amount'].fillna(0.0, inplace=True)
return ohlc
"""
Compute bitcoin OHLC data frame with the given frequency.
@param frame: raw bitcoin price history.
@param freq: target OHLC frequency.
"""
ohlc = frame['price'].resample(freq).ohlc()
close = frame['price'].resample(freq).last().ffill()
for column in ['open', 'high', 'low', 'close']:
ohlc[column] = np.where(np.isnan(ohlc[column]), close, ohlc[column])
ohlc['amount'] = frame['amount'].resample(freq).last()
ohlc['amount'].fillna(0.0, inplace=True)
return ohlc
#load csv from google cloud storage btc prices
%storage read --object gs://testdata-bg-ml/blockchain/mtgoxUSD.csv --variable btcusd
%storage read --object gs://testdata-bg-ml/blockchain/mtgoxUSD.csv --variable btcusd
from StringIO import StringIO
btcdf=pd.read_csv(StringIO(btcusd), header=None)
btcdf.columns = ['dt', 'price', 'amount']
btcdf['dt'] = pd.to_datetime(btcdf['dt'], unit='s')
btcdf=pd.read_csv(StringIO(btcusd), header=None)
btcdf.columns = ['dt', 'price', 'amount']
btcdf['dt'] = pd.to_datetime(btcdf['dt'], unit='s')
btcdf.set_index(btcdf['dt'], inplace=True)
btcdf.sort_index()
btcdf=btcdf[['price', 'amount']]
btcdf.sort_index()
btcdf=btcdf[['price', 'amount']]
remove_bitcoin_date_duplicates(btcdf)
btc_ohlc=convert_to_ohlc(btcdf, freq='1D')
btc_ohlc[len(btc_ohlc)-20:len(btc_ohlc)-1]
btc_ohlc=convert_to_ohlc(btcdf, freq='1D')
btc_ohlc[len(btc_ohlc)-20:len(btc_ohlc)-1]
open
|
high
|
low
|
close
|
amount
| |
dt
| |||||
2014-02-06
|
9.047000
|
165039.858852
|
0.000008
|
207.244967
|
0.250000
|
2014-02-07
|
41.350000
|
159797.250000
|
0.000007
|
6.956182
|
0.010000
|
2014-02-08
|
6.852200
|
132837.779797
|
0.000007
|
42.847200
|
0.066000
|
2014-02-09
|
3952.879440
|
97880.026541
|
0.000006
|
6.594978
|
0.010000
|
2014-02-10
|
43.333572
|
174000.000000
|
0.000005
|
7.525331
|
0.012922
|
2014-02-11
|
87.968410
|
88007.660000
|
0.000006
|
308.289536
|
0.532672
|
2014-02-12
|
102.511593
|
253297.287595
|
0.000005
|
21.240000
|
0.040000
|
2014-02-13
|
5.400370
|
126467.532664
|
0.000005
|
1804.680000
|
4.000000
|
2014-02-14
|
23.853474
|
171746.092896
|
0.000006
|
851.192311
|
1.991000
|
2014-02-15
|
3.847680
|
105175.543367
|
0.000007
|
89.367218
|
0.240882
|
2014-02-16
|
3.661012
|
216377.515944
|
0.000005
|
7.492550
|
0.025000
|
2014-02-17
|
74.591745
|
67943.258101
|
0.000006
|
272.500000
|
1.000000
|
2014-02-18
|
2394.482759
|
57212.401320
|
0.000005
|
295.634055
|
1.006243
|
2014-02-19
|
2.936000
|
36397.654926
|
0.000006
|
1308.491450
|
5.000000
|
2014-02-20
|
14.273712
|
58500.000000
|
0.000006
|
20.074046
|
0.179719
|
2014-02-21
|
89.295960
|
60000.000000
|
0.000005
|
1.114000
|
0.010000
|
2014-02-22
|
1011.679765
|
56805.147540
|
0.000005
|
2.782257
|
0.010888
|
2014-02-23
|
110.700008
|
35250.000000
|
0.000006
|
196.181870
|
0.632845
|
2014-02-24
|
3.149990
|
126521.979120
|
0.000006
|
1.872930
|
0.010774
|
btc_ohlc['close'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fb44ba5a950>
<matplotlib.axes._subplots.AxesSubplot at 0x7fb44ba5a950>
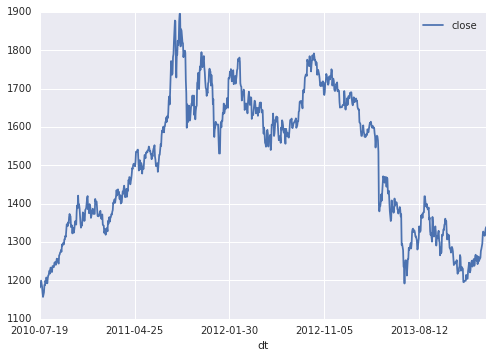
%%sql --module goldusd
SELECT DATE(date) AS dt, price as close
FROM blockchain.gold2usdDaily
WHERE DATE(date) >= DATE('2010-07-17') AND DATE(date) <= DATE('2014-02-25')
ORDER BY dt
SELECT DATE(date) AS dt, price as close
FROM blockchain.gold2usdDaily
WHERE DATE(date) >= DATE('2010-07-17') AND DATE(date) <= DATE('2014-02-25')
ORDER BY dt
golddf=bq.Query(goldusd).to_dataframe().set_index('dt')
golddf.plot()
<matplotlib.axes._subplots.AxesSubplot at 0x7fb4bd3e93d0>
- Gold and Bitcoin prices are normalized in scale.
data = golddf.join(btc_ohlc['close'],how='left', lsuffix='_gold', rsuffix='_btc')
data['gold_scaled'] = data['close_gold']/max(data['close_gold'])
data['btc_scaled'] = data['close_btc']/max(data['close_btc'])
data['gold_scaled'] = data['close_gold']/max(data['close_gold'])
data['btc_scaled'] = data['close_btc']/max(data['close_btc'])
data_scaled=pd.concat([data['gold_scaled'],data['btc_scaled']],axis=1)
data_scaled.plot(figsize=(20,15))
data_scaled.plot(figsize=(20,15))
<matplotlib.axes._subplots.AxesSubplot at 0x7fb4bcf2e510>

- Use log to compare the daily returns of Gold and Bitcoin
log_return = pd.DataFrame()
log_return['gold_return'] = np.log(data['close_gold']/data['close_gold'].shift())
log_return['btc_return'] = np.log(data['close_btc']/data['close_btc'].shift())
log_return['gold_return'] = np.log(data['close_gold']/data['close_gold'].shift())
log_return['btc_return'] = np.log(data['close_btc']/data['close_btc'].shift())
log_return.describe()
gold_return
|
btc_return
| |
count
|
941.000000
|
941.000000
|
mean
|
0.000133
|
0.003735
|
std
|
0.011928
|
3.511937
|
min
|
-0.095962
|
-17.665482
|
max
|
0.048387
|
18.281800
|
_ = pd.concat([log_return['gold_return'], log_return['btc_return']], axis=1).plot(figsize=(20,15), color='darkgreen')
from pandas.tools.plotting import scatter_matrix
_ = scatter_matrix (log_return, figsize=(5,5), diagonal='kde')
_ = scatter_matrix (log_return, figsize=(5,5), diagonal='kde')
log_return.corr(method='spearman',min_periods=1)
gold_return
|
btc_return
| |
gold_return
|
1.000000
|
-0.068212
|
btc_return
|
-0.068212
|
1.000000
|


The scattered plot and correlation matrix indicates that Bitcoin and Gold prices are not correlated much. Comparing with Gold, Bitcoin has much higher volatility, which can make it hard to use for pricing and trading goods and services. From the investment perspective, it could be a good option for diversification.
Conclusion
The simple experimentation tell two stories as follows with data:
- Even Bitcoin transactions are pseudonymous, with enough computing and analytical power, and related information from the web; the identities of senders and receivers, and flows of money could still be traced with good probabilities. The concern about its use in money laundering is much overblown; however, privacy is a valid concern. But people trade privacy for utility or convenience all the time: e.g. the use of social media, credit cards, loyalty programs, etc.;
- Bitcoin offers higher return on investments than Gold between 2010 and 2014 but with much higher volatility.
More stories can be explored with additional experiments and inclusions of richer datasets such as social graphs, economic indices, world bank, and Gdelt. More and more powerful and easy to use tools will allow people imagine and experiment more and therefore expediting the creation of new knowledge. One limitation with BigQuery is that large result set request from Datalab will fail, while there is no problem when loading from Cloud Storage. It is hoped that there will be no such limitation in the near future and integration to other tools such as SPARKS will also be available.
Juypter notebook: https://github.com/pblin/bernardNotebook/blob/master/BTCTX-Copy3.ipynb
Juypter notebook: https://github.com/pblin/bernardNotebook/blob/master/BTCTX-Copy3.ipynb
Hey, this day is too much good for me, since this time I am reading this enormous informative article here at my home. Thanks a lot for massive hard work. blockchain jobs
ReplyDeleteWow i can say that this is another great article as expected of this blog.Bookmarked this site..
ReplyDeletebuy Bitcoin in Nigeria
Thanks for another wonderful post. Where else could anybody get that type of info in such an ideal way of writing?
ReplyDeleteбиткоин на сбербанк
In https://hypersphere.ai we believe that the next era of the digital economy can be shaped around a set of blockchain design principles, which can be used for creating software, services, reinventing business models, markets, organizations, and even governments.
ReplyDeleteIn https://hypersphere.ai we believe that the next era of the digital economy can be shaped around a set of blockchain design principles, which can be used for creating software, services, reinventing business models, markets, organizations, and even governments.
ReplyDeleteIn a world of Big data, the need for infrastructure that can handle the huge amount of data is a must. As a result,big data analytics infrastructurehas become a critical component in the world of data processing.
ReplyDeleteMmorpg oyunları
ReplyDeleteınstagram takipci satin al
Tiktok jeton hilesi
Tiktok jeton hilesi
Antalya Sac Ekim
referans kimliği nedir
instagram takipçi satın al
metin2 pvp serverlar
instagram takipçi satın al
üsküdar samsung klima servisi
ReplyDeletependik vestel klima servisi
kadıköy mitsubishi klima servisi
üsküdar daikin klima servisi
kadıköy alarko carrier klima servisi
maltepe daikin klima servisi
kadıköy daikin klima servisi
kartal toshiba klima servisi
kartal beko klima servisi